
User:Legoktm/How to Run a Top-10 Website, Publicly and Transparently
At the Hackers On Planet Earth (HOPE) 2022 conference, I gave a talk titled: How to Run a Top-10 Website, Publicly and Transparently. You can watch a recording above (download from Commons) or on YouTube. The slides are available on Commons (direct PDF link).
Below is a transcript of my talk. It is mostly what I literally said, edits to clean up the grammar, wikify, etc. are all welcome and appreciated.
Slide 1: Abstract
[edit]The room volunteer read the abstract out, introducing me.
Wikipedia is the only top-10 website that is operated by a non-profit, but more importantly, runs fully transparently. Literally anyone can view detailed monitoring graphs for individual services and servers, see alerts fire in real time, and watch as engineers deploy code and debug problems live. It's not a one-way street. Participation from volunteers is encouraged and welcomed, with the Wikimedia Foundation giving out server access to trusted volunteers, allowing them to view private logs and deploy changes. Even amongst smaller or other non-profit/public interest websites, this level of transparency and openness is really unheard of. Yet it is key in what has made Wikipedia such a force for good and, really, the Internet a better place. This talk will discuss the advantages and disadvantages of running a website in this way, including looking at case studies where this level of transparency enabled volunteers to provide key insights that fixed bugs and outages, saving the day.
Slide 2: Introduction
[edit]QR code: https://www.wikipedia.org/
Today we’re going to talk about Wikipedia, if you couldn’t guess what the top-10 website was. I hope all of you know what Wikipedia is. It’s a free encyclopedia. The main goal of this talk is to discuss transparency. Each slide has a QR code where you can find the resources on that slide, if it’s a dashboard, a graph or a chart or something like that. I’m not sure you’ll be able to scan them here but at the end there’s a very big QR code with links to the slides.
Slide 3: Wikipedia is...
[edit]So Wikipedia is an encyclopedia. You know, the things that they used to print on dead trees. It’s primarily edited by volunteers. It’s available under a free Creative Commons license. You can take the content and reuse it and remix it as long you attribute it that it came from Wikipedia.
The goal of Wikipedia is really to compile the sum of all human knowledge. And that’s a pretty daunting task, you know, on the left that’s a picture of the what is the remains of the Library of Alexandria, which at one point the biggest collection of human knowledge. It’s a pretty daunting task but a lot of people are working hard and are up to it. And as a side effect, you know we really make the internet not suck – in my opinion.
{kind=link}
Slide 4: We are only 5% there
[edit]QR code: https://www.wikidata.org/wiki/User:Emijrp/All_Human_Knowledge
Just to give an idea of the scale of the problem, estimates by looking at topic areas suggest that we’re about 5% done with collecting all of human knowledge. And I think that whenever I go on Wikipedia, no matter what I look up I’ll find something. Yet to think we’re only 5% there really gives an estimate of the magnitude of the task that’s in front of us.
Slides 5-10: Transparency is core to Wikipedia
[edit]QR codes: https://en.wikipedia.org/wiki/Webb%27s_First_Deep_Field https://en.wikipedia.org/w/index.php?title=Webb%27s_First_Deep_Field&action=history https://en.wikipedia.org/w/index.php?diff=1098391691&oldid=1098390994&title=Webb%27s_First_Deep_Field&type=revision https://en.wikipedia.org/wiki/Talk:Webb%27s_First_Deep_Field
First I want to talk about how Wikipedia operates. You know, just building the encyclopedia and we’ll get to the technical part afterwards. Transparency is a really a core principle of Wikipedia itself.
So this is the article for Webb’s First Deep Field, as it looked about a week ago. It actually looks much better now. It was the first image taken by the James Webb Space Telescope. You can read the article, it’s a nice article explains the picture, the background.
But in the top right there’s a little tab that says “View history”. And if you click on the tab it’ll show you the history of the of the page and this is, again, the page from a week ago. Then you can go to through and look at each individual revision of why people made the the change and you can look at the diff of the change itself. So this diff is someone just adhering to the manual of style and changing the numeral six to be spelled out s-i-x.
That’s all great, but it doesn’t really explain like how things happen or why things happen. So there’s another tab that says “Talk”. And that’s really where all the discussions happen on Wikipedia. Each page has an associated talk page that you’ll find some of these discussions on.
And people ask different questions, discuss the validity of different sources, they’ll see if something is phrased properly or can be phrased better. Or whether something is unclear or jargony or could be better.
This is the heart of the collaborative spirit of Wikipedia, which is that if you’re not sure of something instead of making the edit, you can just discuss it with other people.
Slide 11: Technical infrastructure works the same way
[edit]Really the technical infrastructure works the same way. We adhere to the same principles of collaboration transparency and openness.
Slide 12: Technical infrastructure is...
[edit]Just at a glance, Wikipedia is the 7th most visited website. And I got that stat from Wikipedia, so I don’t know if it’s true /s. It’s maintained by a collaboration of volunteers and staff members. All of the source code is available under free licenses, the majority of it is under the GPL, a copyleft license. Like I said, it’s developed in a collaborative manner that you can observe and what I’ll walk through today.
Slide 13: Naming things is hard
[edit]But first a quick segue. Naming things is a hard computer science problem and Wikipedians kind of suck at this.The globe logo is Wikipedia, the encyclopedia, what you’re really familiar with.
In the middle is Wikimedia, it’s the Wikimedia movement is a social movement designed to spread free knowledge. But it’s also the name of the non-profit organization that maintains trademarks, legal status and runs the servers. That’s the Wikimedia Foundation or WMF. Just as an analogy, Wikimedia is to Mozilla as Wikipedia is to Firefox. So that’s the relationship.
If you flip "Wikimedia" around, you’ll get "MediaWiki", which someone thought was a brilliant idea of how to name the wiki software that powers Wikipedia and hundreds of other wikis around the internet. I may use them interchangeably, this is kind of what it is. Hopefully it’ll make sense.
Slide 14: Brief history
[edit]I’ll start with a brief technical history of where Wikipedia came from and that’s what the Wikipedia homepage looked like roughly in November or December 2001. There was a dot-com company called Bomis and one of their side projects was Nupedia, which was a public encyclopedia but everything had to be reviewed before it could be published. It was very slow, and so they decided to create a project called Wikipedia, where anyone can edit and eventually once the articles are good enough quality, we’ll move them over to Nupedia. A few months into the project, Wikipedia had hundreds if not thousands of articles and Nupedia had 60 or 70. It was very clear which project won. At this time the servers where in San Diego, California, owned by this for-profit company called Bomis but volunteers got access.
Within a few years, the leaders of Bomis, including Jimmy Wales, realized how important Wikipedia was, not just as a commercial thing, but as a resource for public good. They split it off into the Wikimedia Foundation as a non-profit, which would safeguard the legacy of it going forward.
Then in 2004, the servers would move to Tampa, Florida. That was primarily because the co-founder of Wikipedia, Jimmy Wales, lived there, and he was the one who installed the first Tampa servers. Coincidentally this was also when the first offsite backup of Wikipedia was taken because they were afraid of hurricanes. It is kind of wild to think today that no one bothered to take a backup of Wikipedia for 3 years knowing how important it is today. We were one failed hard drive away from not having Wikipedia. Or having to start all over.
Slide 15: Datacenters
[edit]QR code: https://wikitech.wikimedia.org/wiki/Data_centers
Today the story is very different. There’s 6 different datacenters around the globe that serve Wikipedia to users. There are two core datacenters in Virginia and Texas that run the MediaWiki software and serve the wiki platform. There are 4 caching point-of-presence datacenters that are in San Francisco, the Netherlands, Singapore and the new one just opened in up in France earlier this year. And it’s starting to serve traffic.
Slide 16: How it works
[edit]QR code: https://upload.wikimedia.org/wikipedia/commons/b/b3/Wikipedia_webrequest_flow_2020.png
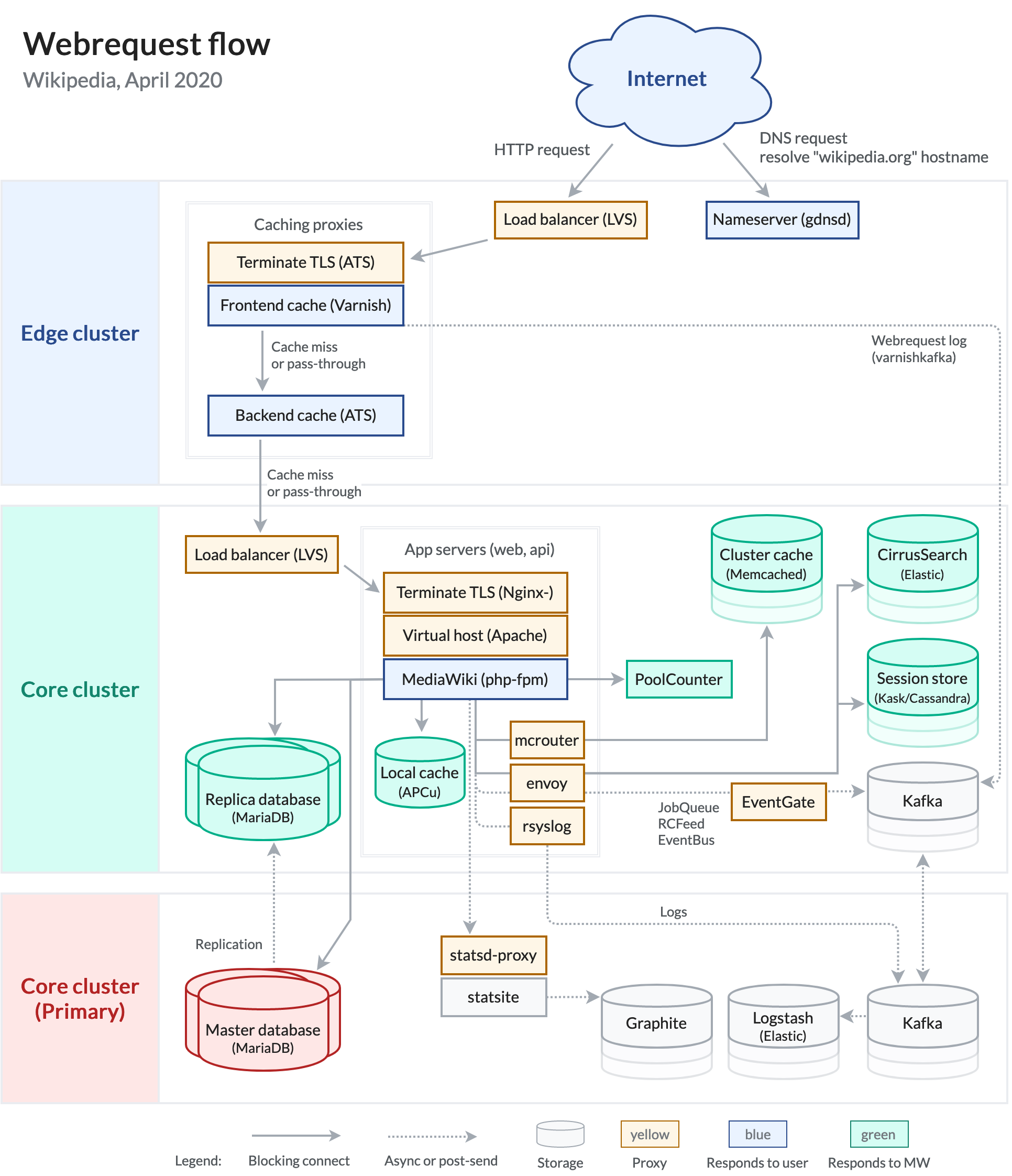{kind=link}
This is an overview of the technical architecture of how your web request flows, starting from the caching layer to the application servers and how it hits the storage layer. I’m not going to explain this, I’m primarily showing this for two purposes.
One to give you an idea of the complexity of the technical stack. You can see there’s a lot of different components, there’s a lot of caching layers and ways that data moves through the flow. The second thing is to show you this diagram is publicly available on the internet, you can read it, you can look at it. It gets updated every few years or so as technology changes.
If you go to our technical wiki, which I’ll link later, you can just type in any of these different components whether its the backend cache or how we use things like mcrouter and envoy. You can just type them into the wiki and you’ll find all of our technical documentation on how we use it, what we use it for, where it’s deployed, where you can find the configuration. All of that is publicly available.
Slide 17: Today's landscape
[edit]These are the main technical points you get in that I’ll go over today.
The first is where we host our code. That is this code review system called Gerrit, which we mirror to GitHub for convenience and to make it easier for people to find.
We publish our metrics and statistics at grafana.wikimedia.org.
Our bugs are tracked in a system called Phabricator and you can see the URL.
Our documentation is kind of spread out, we have two different wikis, wikitech.wikimedia.org which is mainly focused on the Wikimedia-specific documentation and how we deploy things. MediaWiki.org is really about the MediaWiki software, which can be used by anyone but has stuff that is applicable to how Wikipedia uses MediaWiki. doc.wikimedia.org is another place for documentation, that’s mostly auto-generated documentation from code.
Slide 18: Gerrit, Git and code
[edit]In the last 90 days, we saw around 13,000 patches submitted from over 350 different authors. Some of whom are staff, and some of whom are volunteers. All patches to the MediaWIki codebase have to be approved by someone with “+2” rights. Basically you vote “+2” on the change, and it will get merged if it passes CI.
Code gets deployed once a week, we create a branch and that branch is progressively rolled out from the smaller wikis to the biggest ones, including the English Wikipedia. We call that the deployment train.
All the servers are maintained a system called Puppet, that code is deployed immediately. I’ll talk about Puppet a little bit later.
Slide 19: Who submits MediaWiki patches?
[edit]QR code: a very long URL (TODO)
Who is submitting MediaWiki patches? Remember how I said it’s a collaboration between staff and volunteers. Aside from the fact that a dude named Sam is incredibly awesome, it’s actually a pretty clear breakdown: about half the people on the list are staff, and half are volunteers.
When I looked at the actual breakdown of everyone it was around 53% of patches are submitted by staff, and the rest come from volunteers. So it actually is pretty close equilibrium between staff and volunteers.
Slide 20: Who approves MediaWiki patches?
[edit]QR code: https://federico.kapsi.fi/crstats/core.txt
On the flip side, who is approving these patches? It’s actually pretty similar, in the top six people, half are staff and half volunteers. Once a patch is merged it’ll automatically get deployed, so volunteers actually do have significant power from reviewing patches to getting them deployed into production.
Slide 21: Puppet
[edit]Puppet is a way to declaratively state what should be installed or running on a server. It’s similar to Ansible and other tools in that category. It basically is root – Puppet runs as root – so it’s limited to our Site Reliability Engineers (SRE) and a few volunteers who also have root.
The puppet code is public, you can find the Gerrit repository but all the passwords and secret keys are in a private repository that only exists in the production servers.
Other people who don’t have access to servers can test their Puppet patches in virtual machines
Slide 22: Puppet
[edit]If you’ve never seen Puppet code before, this is kind of what it looks like. It’s a mishmash of Ruby syntax with Puppet’s own syntax. This file is how we deploy MediaWiki webservers.
Slide 23: Cloud Services
[edit]QR code: https://en.wikipedia.beta.wmflabs.org/wiki/Main_Page
Like I mentioned, anyone can grab our Puppet code and test in a virtual machine. We have another team called Cloud Services that provides computing resources, which is an OpenStack deployment, for volunteers and staff.
You can take the same Puppet code that is running in production and you can just spin up a VM, apply the Puppet role and you can be, roughly as you close as you can, running the same exact code that’s running in production on your VM. The only difference is you don’t have any private user data, so we can give out access to this VM that is running, again, nearly identical code, to anyone. This means it’s really easy for volunteers to test their code, and have a simulated working environment using the same system that is running in production. It really makes it a lot more accessible to contribute.
One of the key features is we have this “Beta Cluster” which is a replica of some of the production wikis that we have. It’s running the latest version of MediaWiki, as patches have been merged into master to catch different integration issues. And again, we can give out access to this beta cluster where people can test their MediaWiki code or debug problems in MediaWiki code. We can give out access much more liberally than we do on production servers, just because there’s really no private user data here.
Slide 24: DB replicas
[edit]QR code: https://quarry.wmcloud.org/query/45187
In a similar vein, we have database replicas. Most of the database stuff is stored in MariaDB so we have redacted replicas of these databases available Cloud Services VMs. If you want to do stuff locally, you can set up an SSH tunnel.
We have all these rules that strip all of the private data out of or NULL the fields or zero them and then return the rows that are public. Now what’s the next step after that?
We have a web tool that allows you to just run SQL queries straight from the web. It’s like PHPMyAdmin but actually secure. One of the really cool things is that once a technical user who understands SQL writes a query, we see non-technical users, or, I don’t even consider them non-technical, but “traditionally non-technical users,” will just start learning SQL via copy-paste-modify. They’ll start tweaking the queries, first it’ll be strings that are really easy to modify, then they’ll start adding new conditions or copy-pasting from other queries, combining them together.
And it’s really cool to see just because we’ve made this resource available people who consider themselves traditionally non-technical users or don’t have a computer science or programming background are actually writing SQL queries to get data based on the maintenance tasks that they want to do on wikis.
Slide 25: Open statistics
[edit]QR code: https://grafana.wikimedia.org/d/-K8NgsUnz/home?orgId=1&viewPanel=2
Shifting gears, like I said earlier, we publish most of our statistics and metrics. This is how many requests per second we’re getting globally. As the 7th most visited website, that amounts to, at peak, 130,000 requests per second. The shape of the graph is actually people being awake and going to sleep. That’s how our traffic patterns are determined.
Slide 26: Open statistics
[edit]QR code: https://grafana.wikimedia.org/
These are just some more statics, we have the total request volume, how many errors we were serving, and you can see in the error chart we were clearly having some problems at the beginning of it before they zeroed out. Another metric we measure is successful wiki edits. If everyone stops editing, that means there’s a problem on the wikis.
Slide 27: Even for individual servers
[edit]You can also get a breakdown for the health of individual servers. This is mw1312, which is a MediaWiki application server living in the Virginia cluster. You can see the CPU, the memory usage, networking, and if you scrolled down further you could see temperature, load averages. The breakdown for every server and virtual machine in our production cluster is on this page.
Slide 28: Or for databases
[edit]QR code: https://grafana.wikimedia.org/d/000000278/mysql-aggregated?orgId=1
And you can also look at the database layer. This is an aggregated shot of all of the database rows that are being written and read to every single one of our database clusters.
Slide 29: Or entire datacenters
[edit]And you can also look at the datacenter level. This is our Singapore datacenter, and you can see Asia is clearly waking up and starting to access more data on Wikipedia, so that is why the networking charts are going up. You can look at basic how many servers there are in our datacenters. All this information is publicly accessible and anyone can just start browsing through and learning things.
Slide 30: Public communications
[edit]Like Wikipedia has talk pages, most of the communication around development happens in public as well. We have a traditional mailing list, called wikitech-l. Then we have Phabricator and Gerrit comments. Then we have a whole host of IRC channels on the Libera Chat network. The biggest channels are bridged to Matrix to provide a nicer user interface for people who aren’t used to IRC.
Slide 31: Phabricator transparency
[edit]QR code: https://phabricator.wikimedia.org/T275752
I want to walk through an example of how transparency was key in solving an outage. This happened towards the end of 2021.'
Users can upload files to Wikipedia and we have a maximum file size of 4GB. But like I mentioned earlier, we have two core datacenters, so when you upload a file, in the backend it’s being copied over to both datacenters, and it ends up in a system called Swift, which is the OpenStack version of S3. Your file is uploaded very quickly to the local datacenter and then it has to take the extra code of going from one datacenter to another, so the speed of light from Virginia to Texas.
What we found was that, for whatever reason, files were going to the other datacenter very slowly. It was about 2Mbps and we have a 300 second timeout, which basically gives you a 600MB file. And people are uploading files up to 4GB in size. This is a problem for any large file upload.
This coincided of our upgrades from Debian Stretch to Debian Buster. So something in that large upgrade caused these file uploads to slow down. We didn’t have a good clue of what it could be.
Slide 32: Phabricator transparency
[edit]I was the lead person investigating this, my first step was to try and reconstruct. Can I minimize the code or use a plain curl command? Can I get the upload to finish in time or will it be really slow? Also can I just write a very minimized PHP reproduction by stripping the code out of the two main classes that are responsible for handling file uploads? Can I minimize it down to just the very basics so that way it’ll reproduce the issue so we can run it under strace and a few other things?
What I found was that when I ran it with the command line curl it finished instantly, but when I ran it with the PHP code, it was just still slow. Which was great, now I have two different things that I can compare. So in the Phabricator ticket I pasted everything I was doing, all the commands I was running and all the output that I got.
Slide 33: Phabricator transparency
[edit]I tried a little more debugging, like if I switched from using curl in PHP to stream wrappers, it still works but stream wrappers have a much smaller max file size. I noted that as part of the upgrade we had upgraded libcurl from 7.52 to 7.64. So there were going to be changes and maybe it was one of those changes.
My final strace showed it was calling fread(3) a lot and I thought that was suspicions.
Slide 34: Phabricator transparency
[edit]Then I went to sleep and my colleagues took over. They said my hypothesis was correct but it’s not like the fread syscalls that are causing it, it’s the fact that we’re making 820 roundtrips between the datacenters, because we’re sending the file in really small chunks.
The roundtrips will add up a lot just because we’re in a different datacenter and that’s what was causing it to take so long. They did some more statistical analysis in Wireshark that showed this is clearly the problem, that we’re sending too many roundtrips and it’s going too slowly.
Slide 35: Phabricator transparency
[edit]A volunteer who was following the ticket, and this volunteer has no server access, no access to private data, and probably doesn’t have a full understanding of the technical architecture. But they’re reading the ticket, they’re following along and all of us commenting so far had been doing so in a verbose way where everything we were doing was written out.
The volunteer asks, “But the commandline curl output is using HTTP/1 and the libcurl output from PHP is using HTTP/2. Can we either force one of them to use HTTP/2 or force HTTP/1?” And that was actually the issue.
The use of HTTP/2 is causing it to do way more roundtrips than necessary and as soon as we forced it to use HTTP/1, as the volunteer noticed was wrong, that immediately fixed the issue. The uploads finished incredibly quickly.
At that point it was “OK, just write a patch to force it to use HTTP/1 and we’re set.” Then the volunteer in a later comment actually found in the libcurl changelog where it says they’re going to default to HTTP/2 if the method is not explicitly specified, in the changelog period from stretch to buster. So that totally validated our theory and at the same time this came from a volunteer.
Slide 36: Phabricator transparency
[edit]QR code: https://wikitech.wikimedia.org/wiki/Incidents/2021-11-04_large_file_upload_timeouts
In the end, it was the verbosely pasting publicly, that allowed this volunteer to come up and solve the issue. It’s likely the staff SREs would’ve figured out the real cause eventually, but I think it would’ve taken more time, a few days at least.
We have a full incident report that you can read, and the incident report also links to a really good Cloudflare blog post that explains why in certain conditions, HTTP/2 is actually slower than HTTP/1. So if you’re interested in the technical reasoning behind it, I’d recommend reading that.
Slide 37: IRC channels
[edit]QR code: https://meta.wikimedia.org/wiki/IRC/Channels
Jumping over to IRC, we have a ton of IRC channels. This is the list of technical IRC channels that go from M to T, because that’s how much I could fit into the screenshot. There’s a lot more. You can peruse the list of IRC channels, you can join them, nearly all of them are publicly open and a lot of them are publicly logged, so you can go back and read old conversations.
Slide 38: IRC channels
[edit]These are the main three channels that if you’re interested. There’s the #wikimedia-operations channel, which is the main coordination channel where deployments happen, incident discussion happens.
There’s the #wikimedia-sre channel which is discussion amongst SREs. There’s the #wikimedia-tech channel which is for end-user support and help and people will just often ask questions and have general – anything that fits under technical discussion – is totally on topic there.
We also have a private security channel for dealing with DDoS attacks and active security issues. It is used pretty sparingly just because everyone in that channel also recognizes that using that channel is excluding a significant amount of volunteers and even staff members who aren’t in that channel. And that’s why discussing things publicly is preferred.
Slide 39: IRC transparency
[edit]QR code: https://wm-bot.wmflabs.org/libera_logs/%23wikimedia-operations/20220720.txt
This is from Thursday, this is just a snippet of an IRC log from the operations channel. Taavi, a volunteer, is pinging two of the people who are responsible for the deployment, asking if it can be rolled back because it’s broken, coincidentally again, uploads. Can you imagine going on an IRC channel and pinging someone from Amazon, Google or Facebook saying, hey your deployment is broken, can you please roll back? This level of access is really like, you don’t have that anywhere else.
Within three or four minutes, Jeena says, OK I’ll roll back. And then the deployment tool says, yes, Jeena has rolled back the wikis to a previous version. The deployment tool uses this !log, which means…
Slide 40: Server Admin Log
[edit]QR code: https://twitter.com/search?q=oops%20%40wikimedia_sal&src=typed_query&f=top
All of the entries end up in what we call the Server Admin Log. This is a log for any action that happens on a server that isn’t going to be reflected anywhere else, like when you merge a patch it gets logged in Git. But for a lot of options like rebooting a server or adjusting some configuration in a database, like etcd, or depooling a server, those things aren’t reflected anywhere else besides the server in your ~/.bash_history.
So the Server Admin Log collects all of that. All of our deployment tools will automatically send logs to the Server Admin Log. You just type in !log in IRC and it’ll go to a wiki page. It’ll go to Mastodon and Twitter. On the right I have the Twitter search for the word “oops” in the server admin log. The other fun one to search is “WTF” and you can see what people were frustrated about five or six years ago.
The Twitter and Mastodon integration is kind of new, but the wiki archives go back to June 2004. You can see what Wikimedia sysadmins have been doing all the way starting in June 2004 up until literally right now. There’s pages of archives and you can search through them, you can read through them, you can see reverting stuff, dealing with outages, not knowing what they’re doing, or you can just see general maintenance, like pooling and depooling servers. So there’s a lot of valuable history there.
Slide 41: IRC transparency
[edit]QR code: https://wm-bot.wmflabs.org/libera_logs/%23wikimedia-operations/20220720.txt
The other thing that’s really cool about IRC is that in the operations channel most of our alerts and monitoring will show up there. We use a combination of icinga and alertmanager to do notifications. This is when a blip in networking caused icinga to think a bunch of hosts were down, just because it couldn’t reach them.
The two lines I bolded have the word #page in them, that’s special because it means that SREs were paged for that so you can see that SREs have already been paged and you don’t need to try and ping someone independently that all of these alerts have gone off. Both of those are database servers, that’s why triggered pages. At the very bottom you can see Reuven going "uhoh" because he’s been paged and within a minute he’s on IRC, like why are all these servers disappearing?
Slide 42: Private information
[edit]So far everything I’ve talked about has been public. There’s a lot of information that’s public that’s on the wikis, in Phabricator, and IRC that you all can access. But there is some private information that we do have.
Overall Wikipedia has very little private information compared to most websites. We don’t collect your address, we don’t collect your credit card information, we don’t collect your phone number. Even registering with your email is optional, literally the only private thing we have is your password, and possibly your email address if you chose to give it. So there’s very little private information.
But still volunteers need to sign an NDA to get access to debug logs, web request logs, we have slow SQL queries that can be used as DoS vectors. Or security tickets. The NDA is not even secret, you can read the terms on the wiki itself, the bar for signing an NDA has been lowered over time. Previously you needed C-level signoff on everything to give a volunteer access and now any WMF employee can vouch for you and then the legal department will prepare the NDA and get it signed.
When I checked earlier this week, there were exactly 100 users in our nda LDAP group, which controls it. And all those people are volunteers, none of them are Foundation staff, which has a separate group. So that really shows the scope of people, even for this private information we’ve been able to expand the access for it.
Slide 43: Server access
[edit]Server access, not like the little kitten has gotten, but real SSH access, again, volunteers need to sign an NDA and go through a form of deployment training. This access is controlled by the Release Engineering team, which is the one that coordinates and manages most of the deployments.
There are about 7 volunteers with MediaWiki deployment access, who can deploy patches, security patches, they can inspect the state of code, they can do interactive debugging.
There are only 2 volunteers with root – one of them is me – and me and the other person who’s a volunteer with root, we are both former staff. In the past there used to be more volunteers with root, which I think was a really good equalizing principle and good governance that it was a mix of volunteers and staff who are making these root-level decisions. But over the years the SRE team has grown more professionalized and it’s expanded a lot that’s really hard for volunteers to justify root access because any time you need something with root access, it’s not like “Oh I’m blocked on it,” because you just ping someone and someone on the SRE team will be awake and be able to help you.
I would like to see that change, I think it’s important that there are volunteers with root access, but it’s kind of a practical problem right now.
Slide 44: Transparency is hard
[edit]All of what I’ve talked about so far about like transparency and access, I think it’s important to not understate how hard this can be to keep up, to keep this culture up. It is a constant fight to keep things transparent.
A lot of the systems we have are designed to be open by default, like Gerrit is public, Phabricator is mostly public, all of our statistics are public, our IRC channels are public. So as long you use those venues, your things will be public by default.
But regardless of this, people trend towards closed platforms. People want to use Slack instead of IRC. People want to use Google Docs instead of wiki pages. It can be difficult to constantly be the source of friction, being like “Hey I know you shared a Google Doc with me, can you just post it on the wiki and I’ll give you my feedback there?” Or if someone pings you on the internal WMF Slack, “Actually this is a discussion we should be having in public, so that way volunteers can participate, can we move it to IRC?” And it’s difficult especially when you’re being pinged, and the answer is “yes”. Are you really going to force the person to context shift just to give them that answer?
There are some things that have to be private, like legal advice. Lawyers can only give legal advice to the company, so the only people can read their detailed advice are Foundation staff, and then the Foundation staff have to summarize it to the volunteers and be like “This is what the lawyers said. I’m sorry I can’t explain it to you, this is what we have to do, because the lawyers said so.” This can be frustrating, especially if you disagree with the lawyers.
People can really be intimidated by having to do everything publicly. Wikimedia has a very strong component and value of privacy and we’re asking everyone to do everything in public. Once these things are public on the internet, they’re archived forever and we keep our own records forever. The idea that any mistake or silly comment or bad joke, especially if it has aged poorly over time, is going to be public and archived forever. Do you really want that?
I was in an interview for my new job and the person interviewing me pulled up a random wiki page that I had worked on, like a technical proposal, being like, “All of these users didn’t like your proposal, what do you have to say about that?” I was like, oh my goodness, yeah they said that, they didn’t like my proposal, I discussed it. The idea that any future employer or interviewer can pull up what you’ve been working on and read all your comments – I think it’s kind of intimidating.
I think the one thing that works in our favor is that we’re very happy for users to be publicly anonymous. There are people with merge rights to MediaWiki we don’t actually know their real name or real life identity, it’s just that they’ve done good work, they’ve become trusted in the community, so we’ve given the rights. To sign the NDA you do have to use your legal name, but the legal name can just be restricted to the lawyers and it can be kept private. The fact that we allow people to contribute anonymously does mitigate that a bit. But working in public can turn people off and is something to keep in mind.
Slide 45: What can you do?
[edit]Finally, what can you do? I think this model for transparency is not something that is uniquely special to Wikimedia, that only we can do it. I think that any other public interest website should try and do the same. Even if you do it for your personal website, I think that’s good for the internet. I think this level of transparency helps make the internet not suck.
The thing is to start gradually. Don’t try to make everything public at once, that can be really difficult and a culture clash. I find that documentation is the easiest place to start, and I will say that wikis are the best of course, but even markdown files in a Git repository are decent as well. As long as it’s there.
Just start writing things down, even if it’s a list of “These are the server components we use. We use nginx, we use Python with gunicorn and it’s managed by systemd units.” Even if that’s literally the list, it’s a place to start and it’s much easier to iteratively add things than it is to start from scratch.
Once you start building your community other people will start documenting things for you. And I would also say it’s OK to lose control. When it comes to our code we’re very picky about the syntax and the spacing and formatting and how methods are named and all of that. You have to lose control with wikis, people will organize it the way they want, as long as it’s not destructive, then accept it and just go with it. The important thing is people are contributing and eventually you’ll move in the right direction and you’ll grow to like it.
Once you’ve started getting some documentation done, start publishing your server configuration. What does your Apache configuration look like? What does your nginx configuration look like? What are the systemd units that you’re using? I like analogizing this to how people publish their dotfiles. People want to show off the cool tricks they have in their ~/.zsh and their ~/.bashrc and there are lists of awesome dotfiles where you can see a list of other people who have really cool dotfiles and how they’ve customized their bash prompt. People have really cool tricks hidden in their server configuration, you should publish that too. There’s a lot of material that could be learned, that’s interesting to look at. The catch is you have to figure out how to separate your passwords and private data from that, but that’s a best practice anyways, to separate private data from data that’s...not private.
Finally, track issues publicly. This can be difficult because often times you don’t want to show that you have bugs. But this is also the best way to get people started, to show it’s not perfect and there’s room for improvement. Even if you just literally write a line like “this is buggy” and file that as the issue, that’s fine as long it’s there. You don’t know, if there’s a volunteer or we’ve had cases where the upstream author will see the ticket in our repository and be like “Hey I’m the upstream for this. Can I help you solve whatever this problem is?” Even though you just have one line, then you are prompted to go into more detail about what the issue is. Having an easy or good first task category is a good way to get started.
In general, keep up the fight for transparency! Be the little source of friction. Choose your battles of when you want to ask people to document something publicly, or when you want to have a conversation in public.
Slide 46: What can you do?
[edit]QR codes: https://www.mediawiki.org/wiki/How_to_become_a_MediaWiki_hacker https://developer.wikimedia.org/
If you’re interested in contributing to Wikipedia, we have a lot of work to do. Like I mentioned, we’re 5% there. Whether you want to edit the projects or whether you want to contribute technically, there’s a lot of work. The easiest way is to just lurk in our IRC and Matrix channels. Something might catch your attention, someone might be asking a question about the thing you have subject matter expertise in. Or you might just find the conversations interesting.
I have two QR codes on this slide, the first is the guide of how to become a MediaWiki hacker, which walks you through setting up Git, how to use our Docker or VM based MediaWiki setup, and the second is this brand new Wikimedia Developer Portal, which gives you a lot links of different other projects that are not explicitly MediaWiki that still need contributions. We have bot frameworks, different developer tooling, there’s a lot of stuff out there.
Slide 47: Thank you
[edit]QR code: https://meta.wikimedia.org/wiki/User:Legoktm/HOPE_2022 (this page)
Thank you! That’s the QR code for the slides, that’s different ways you can reach me if you have questions.